Question
Which of the following statements is/are not true regarding I?
Study the following information carefully and answer the given questions: There are nine persons
i.e. A, B, C, D, E, F, G, H and I are sitting in a linear row. All of them are facing in the north direction. B sits at the middle of the row. Two persons sit between C and
B. E is an immediate neighbour of C and sit at the end of the row. H sits third from the left end of the row. D is an immediate neighbour of H. Number of persons sit to the right of F is equal to the number of persons sit to the left of H. I sits exactly between B and F. At least one person sits between G and A who does not sit at the end of the row.
i.e. A, B, C, D, E, F, G, H and I are sitting in a linear row. All of them are facing in the north direction. B sits at the middle of the row. Two persons sit between C and
B. E is an immediate neighbour of C and sit at the end of the row. H sits third from the left end of the row. D is an immediate neighbour of H. Number of persons sit to the right of F is equal to the number of persons sit to the left of H. I sits exactly between B and F. At least one person sits between G and A who does not sit at the end of the row.
 Twopersons sit betweenCand B. Asperthisstatement,therearetwopossiblecases andthearrangementwill look like this:
Twopersons sit betweenCand B. Asperthisstatement,therearetwopossiblecases andthearrangementwill look like this: 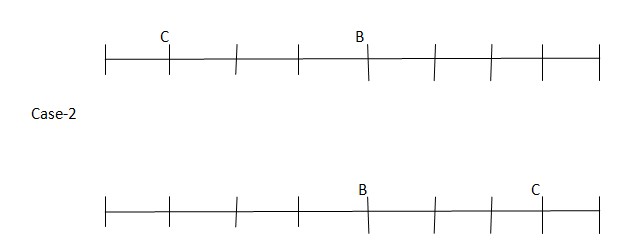 EisanimmediateneighbourofCandsit at the end ofthe row. H sits third from the left end of the row.As per this statement, the arrangement will look like this
EisanimmediateneighbourofCandsit at the end ofthe row. H sits third from the left end of the row.As per this statement, the arrangement will look like this 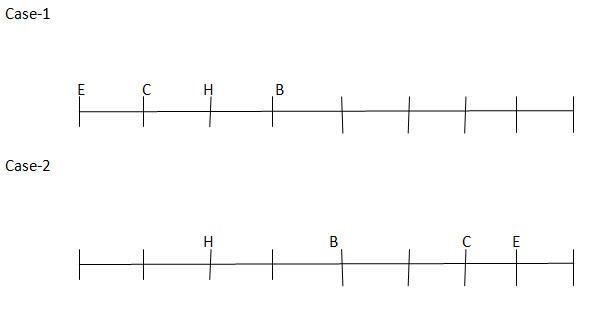 DisanimmediateneighbourofH. Asperthisstatement, CASEII willfurthergetsplitintoone more case and the arrangement will look like this:
DisanimmediateneighbourofH. Asperthisstatement, CASEII willfurthergetsplitintoone more case and the arrangement will look like this: 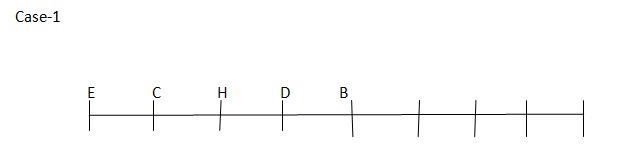 Case-2
Case-2 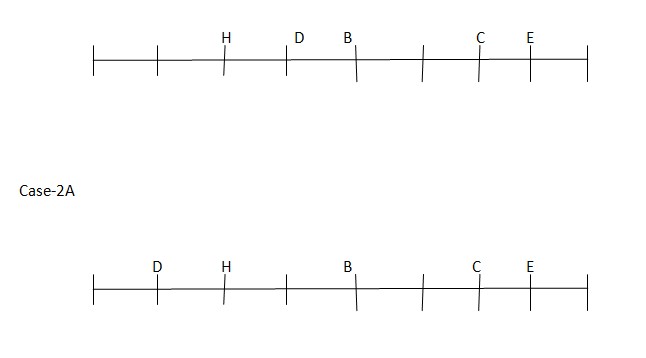 NumberofpersonssittotherightofFisequalto the number ofpersonssit to theleft of H. IsitsexactlybetweenBandF. At least one person sits between G andAwho does notsitat theendoftherow. As per this statement, CASE I and CASE II will geteliminated and we will continue with CASE II (A) andthefinal arrangement will look likethis:
NumberofpersonssittotherightofFisequalto the number ofpersonssit to theleft of H. IsitsexactlybetweenBandF. At least one person sits between G andAwho does notsitat theendoftherow. As per this statement, CASE I and CASE II will geteliminated and we will continue with CASE II (A) andthefinal arrangement will look likethis: 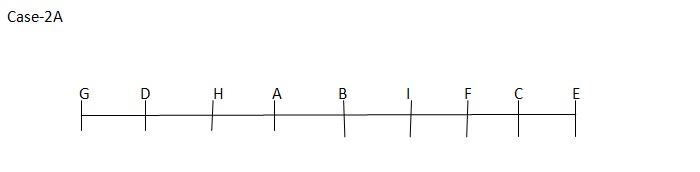
More Seating Arrangement Questions
- Six people, R, S, T, U, V and W are sitting around a circular table facing towards the centre (but not necessarily in the same manner). One person is sitti...
- What is the sum of present age of PAWAN and the one who is third to the right of PAWAN?
- Which of the following is true?
- What is the position of L with respect to F?
- Who among the following person uses HP laptop?
- Eight friends S, T, U, V, W, X, Y and Z are sitting in a straight line facing north, but not necessarily in the same order. U sits third from the left end....
- Six friends Q, N, X, S, R and T are sitting in a row facing north. N and S are adjacent to each other and neither of them is on extreme end. T is sitting t...
- Who among the following sits exactly between A and B?
- Six friends Q, R, S, T, U and V are standing in a circle facing the centre. R is between V and S, Q is between U and T, and V is to the immediate left of T...
- What is the position of V with respect to V’s wife?
Relevant for Exams:
Hey! Ask a query
Please enter email id
The email must be a valid email address.
Please enter Mobile Number
Please enter valid Mobile Number
Please enter your Doubt
