Question
Which of the following statement is true?
Study the following information carefully and answer the below questions. Ten person are sitting in two parallel rows containing five each, in such a way that there is an equal distance between them. In row 1 – F, G, H, I and J sit facing north, similarly in row 2 – R, S, T, U, and V sit facing south. Each person likes different fruits viz. Papaya, Apple, Banana, Mango, Watermelon, Grapes, Pineapple, Strawberry, Orange and Guava. All the information is not necessary in the same order. J sits at one end of the row three places away from the one who likes Strawberry. The one who likes Strawberry sits facing S. One person sits between S and the one who likes Guava. G neither likes Strawberry nor sits facing U. Two person sit between V and the one who sits facing G. G sits immediately right of the one who likes Watermelon. The one who likes Orange and the one who likes Papaya sits together. The one who likes Papaya sits facing the one, who sits second to left of the one who likes Banana. The one who likes Banana neither sits at the end of the row nor sits in the same row of the one who likes Apple. I sits facing the one who likes Pineapple and is adjacent to F. The one who likes Orange sits facing the one who likes Mango. T neither sits facing the one who likes Grapes nor sits facing the one who likes Orange. F neither sits facing the one who likes Banana nor sits facing T. One person sits between U and T.
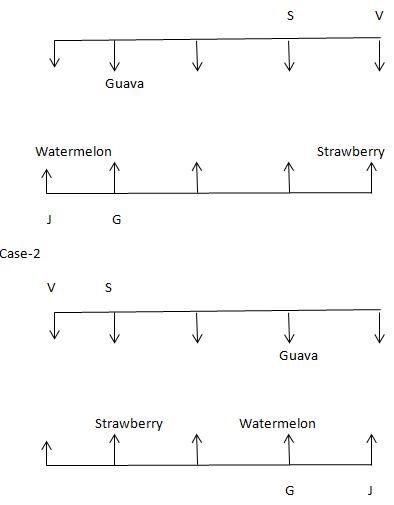 Again, we have: The one who likes Orange and the one who likes Papaya sits together. The one who likes Papaya, sits facing the one, who sits second to left of the one who likes Banana. The one who likes Banana neither sits at end of the row nor sits in same row of the one who likes Apple. The one who likes Orange sits facing the one who likes Mango, that means in case (2a) the one who likes Papaya sits second from right end of row 2, in case (2b) the one who likes Papaya sits second from right end of row 1, case (1) is not valid. I sits facing the one who likes Pineapple and is adjacent to F. F neither sits facing the one who likes Banana nor sits facing T, that means in case (2a) I likes Watermelon and case (2b) is not valid. Based on above given information we have: Case-2a
Again, we have: The one who likes Orange and the one who likes Papaya sits together. The one who likes Papaya, sits facing the one, who sits second to left of the one who likes Banana. The one who likes Banana neither sits at end of the row nor sits in same row of the one who likes Apple. The one who likes Orange sits facing the one who likes Mango, that means in case (2a) the one who likes Papaya sits second from right end of row 2, in case (2b) the one who likes Papaya sits second from right end of row 1, case (1) is not valid. I sits facing the one who likes Pineapple and is adjacent to F. F neither sits facing the one who likes Banana nor sits facing T, that means in case (2a) I likes Watermelon and case (2b) is not valid. Based on above given information we have: Case-2a  Case (1) is not valid as the one who likes Papaya, sits facing the one, who sits second to left of the one who likes Banana & case (2b) is not valid as F neither sits facing the one who likes Banana nor sits facing T. Again, we have: Since, the one who likes Banana and the one who likes Apple doesn’t sit in same row, that means the one who likes Apple sits at left end of row 2. One person sits between U and T. T neither sits facing the one who likes Grapes nor sits facing the one who likes Orange, that means U sits at left of the row 2. As, the only remaining person is R, thus R likes Guava. Based on above given information we have final arrangement as follow:
Case (1) is not valid as the one who likes Papaya, sits facing the one, who sits second to left of the one who likes Banana & case (2b) is not valid as F neither sits facing the one who likes Banana nor sits facing T. Again, we have: Since, the one who likes Banana and the one who likes Apple doesn’t sit in same row, that means the one who likes Apple sits at left end of row 2. One person sits between U and T. T neither sits facing the one who likes Grapes nor sits facing the one who likes Orange, that means U sits at left of the row 2. As, the only remaining person is R, thus R likes Guava. Based on above given information we have final arrangement as follow: 
More Seating Arrangement Questions
- Five products, P, Q, R, S and W, are placed in a row facing towards the east (not necessarily in the same order). R is second to the left of S. P is second...
- Which of the following statement is correct about K5?
- Which of the following person sits sixth to the left of the one who works in company B?
- Six persons- L, M, N, O, P, and Q sit along a circular table and face toward the centre of the table. L sits second to the right of P. Only one person sits...
- If positions of Q and M are interchanged, what will be the position of Q with respect to R?
- X has tuition centre in which place?
- Seven persons R, S, T, U, V, W and X sit in a linear row. All of them face towards south direction. V sits third to the right of W, who sits at one of the ...
- Which of the following statements is/are true?
- Four among the following five are alike in a certain way and hence form a group. which of the following does not belong to the group?
- Four of them following are in the same group, which is not belongs to that group?
Relevant for Exams:
Hey! Ask a query
Please enter email id
The email must be a valid email address.
Please enter Mobile Number
Please enter valid Mobile Number
Please enter your Doubt
